Recently, we had several virtual machines hosted on OpenShift Virtualization experiencing Windows Blue Screen of Death (BSOD). In our situation, the problem was caused by a latency spike within the storage layer. To detect similar guest operating system issues in the future, we decided to utilize the OpenShift Virtualization capability to probe for the health of the the guest operating system and send a Prometheus alert in the event of an operating system crash. This article will walk you through the specifics of such a configuration.
The setup for detecting a crash of the guest operating system consists of two parts. First, we activate a readiness probe for the virtual machines. Subsequently, we define a Prometheus alerting rule that triggers if a virtual machine is not in a ready state. In the next section, we will begin by creating the readiness probe.
Creating readiness probe for virtual machine
OpenShift Virtualization includes a guest agent ping probe feature. This feature has been present since at least OpenShift 4.14, but it remains a Technology Preview in OpenShift 4.19. Update 11/07/2025: The feature became Generally Available (GA) in OpenShift version 4.20. The guest agent ping probe regularly sends a ping request to the QEMU guest agent installed within the virtual machine. In the event of a virtual machine crash (BSOD), the guest agent will be unable to respond, resulting in a failure of the ping probe. Following multiple ping probe failures, Kubelet will update the status of the virtual machine pod to not ready.
The readiness probe must be configured individually for each virtual machine. In this section, we will demonstrate the process of activating the probe for a single virtual machine.
First, create a readiness-probe.yaml file that contains the definition of the probe:
| |
Use the above file to patch a virtual machine. Prior to executing the patch command, substitute the name of the virtual machine you are patching:
| |
Verify that the patch has been applied correctly by displaying the current readiness probe configuration. Prior to executing the get command, replace the name of the virtual machine with your specific instance:
| |
Example command output:
| |
Once the readiness probe has been configured, it is necessary to restart the VM for the changes to take effect. Certain modifications to the VM can be activated through live migration of the virtual machine, however, in this scenario, the update to the readiness probe will not be propagated during the live migration, thus necessitating a restart of the virtual machine. You have the option to restart the VM via the OpenShift Web Console or by using the virtctl command. Prior to executing the virtctl command, ensure that you substitute the name of the virtual machine with your specific instance:
| |
Note that upon restarting the VM with the readiness probe enabled, the VM will not be ready right away; it will only reach a ready state after the readiness probe succeeded. This process may take some time, in our case up to about three minutes, for the VM to become ready. To monitor the state of the VM, you may execute the command:
| |
After about three minutes, the VM becomes ready:
| |
You may also confirm that the configuration of the VM pod now includes the definition of the readiness probe. Prior to executing the subsequent command, substitute the name of the virtual machine pod with the name of your pod:
| |
| |
Following the successful configuration of the readiness probe for the virtual machine, we will proceed to test it practically in the next section.
Testing readiness probe
You can test the readiness probe by manually initiating the Windows BSOD within your virtual machine.
Some versions of Windows automatically reboot after experiencing the the blue screen of death. We would like to turn the automatic reboot off, allowing the virtual machine to stay in a crashed state. To disable the automatic reboot, log into your Windows virtual machine and execute the following PowerShell command:
| |
Restart the virtual machine for the above change to be applied. Once the restart is complete, log back into the virtual machine and initiate the BSOD by executing the following command in PowerShell:
| |
Upon executing the above command, you should now see the Windows BSOD:
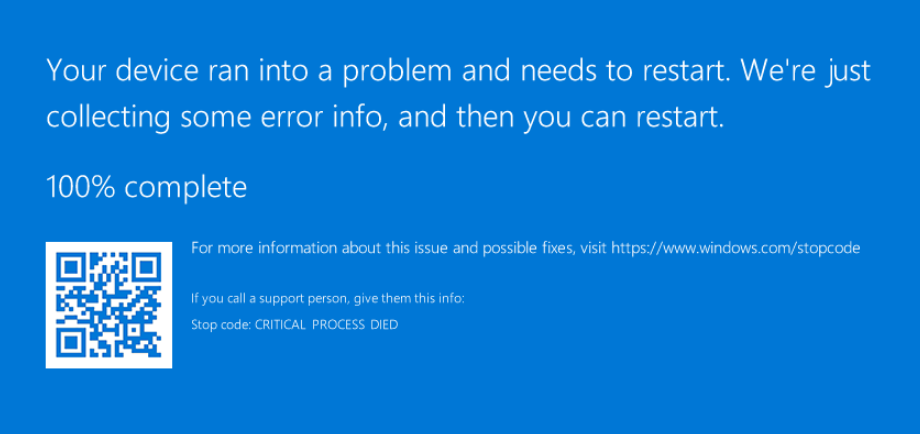
In OpenShift, less than a minute thereafter, the status of the virtual machine pod should change to not ready:
| |
| |
Creating alerting rule
In this section, we will crete a Prometheus alerting rule that triggers if a virtual machine pod is not in a ready state. This rule needs to be defined once for each OpenShift cluster.
First, create a file virtual-machine-pod-not-ready-alertingrule.yaml that contains the rule definition:
| |
Next, apply the alerting rule to the OpenShift cluster:
| |
Once the rule has been applied to the cluster and if there is a VM in the cluster that crashed with the Windows BSOD, you should receive an alert:
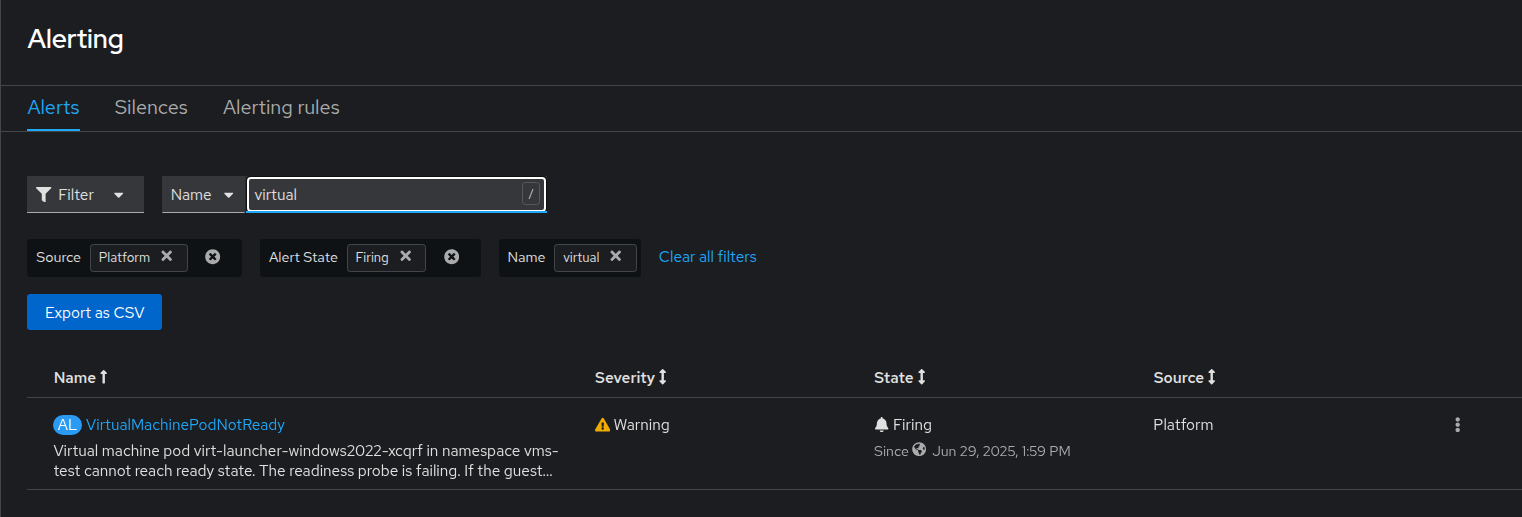
Conclusion
In this blog, we utilized the capabilities of OpenShift Virtualization along with the OpenShift built-in monitoring stack to detect and notify in the event that the guest operating system crashed. We illustrated this process using a virtual machine running Windows Server 2022 as an example. Additionally, I confirmed that the same configuration functions properly for the guest operating systems Windows Server 2016 and Windows Server 2019.
Building on the example provided in this blog post, you can use some additional shell scripting to add the readiness probe to all virtual machines within your cluster. You can also update your virtual machine templates if you would like to include the readiness probe in the definition of any new virtual machine created in the cluster.
Hope you found this article useful. If you have any questions or comments, please feel free to leave them in the comment section below. I would be happy to receive your feedback!