This blog will walk you through the Apache Airflow architecture on OpenShift. We are going to discuss the function of the individual Airflow components and how they can be deployed to OpenShift. This article focuses on the latest Apache Airflow version 1.10.12.
Architecture overview
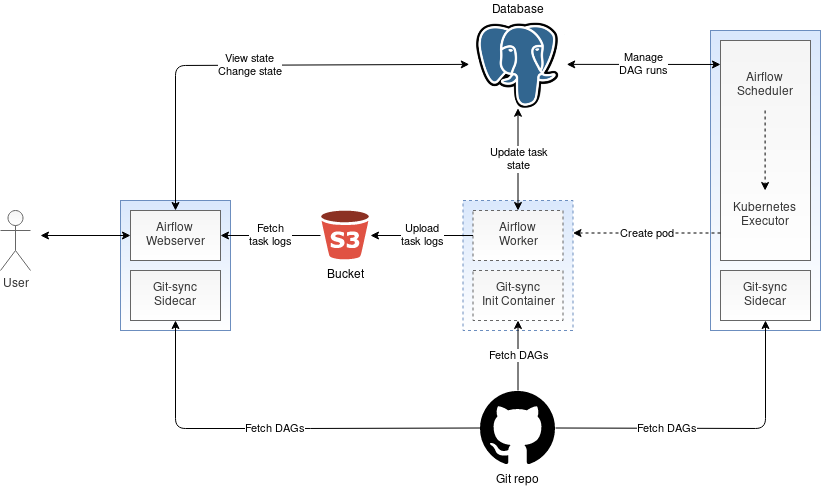
The three main components of Apache Airflow are the Webserver, Scheduler, and Workers. The Webserver provides the Web UI which is the Airflow’s main user interface. It allows users to visualize their DAGs (Directed Acyclic Graph) and control the execution of their DAGs. In addition to the Web UI, the Webserver also provides an experimental REST API that allows controlling Airflow programatically as opposed to through the Web UI. The second component — the Airflow Scheduler — orchestrates the execution of DAGs by starting the DAG tasks at the right time and in the right order. Both Airflow Webserver and Scheduler are long-running services. On the other hand, Airflow Workers — the last of the three main components — run as ephemeral pods. They are created by the Kubernetes Executor and their sole purpose is to execute a single DAG task. After the task execution is complete, the Worker pod is deleted. The following diagram depicts the Aiflow architecture on OpenShift:
Shared database
As shown in the architecture diagram above, none of the Airflow components communicate directly with each other. Instead, they all read and modify the state that is stored in the shared database. For instance, the Webserver reads the current state of the DAG execution from the database and displays it in the Web UI. If you trigger a DAG in the Web UI, the Webserver will update the DAG in the database accordingly. Next comes the Scheduler that checks the DAG state in the database periodically. It finds the triggered DAG and if the time is right, it will schedule the new tasks for execution. After the execution of the specific task is complete, the Worker marks that state of the task in the database as done. Finally, the Web UI will learn the new state of the task from the database and will show it to the user.
The shared database architecture provides Airflow components with a perfectly consistent view of the current state. On the other hand, as the number of tasks to execute grows, the database becomes a performance bottleneck as more and more Workers connect to the database. To alleviate the load on the database, a connection pool like PgBouncer may be deployed in front of the database. The pool manages a relatively small amount of database connections which are re-used to serve requests of different Workers.
Regarding the choice of a particular DBMS, in production deployments the database of choice is typically PostgreSQL or MySQL. You can choose to run the database directly on OpenShift. In that case, you will need to put it on an RWO (ReadWriteOnce) persistent volume provided for example by OpenShift Container Storage. Or, you can use an external database. For instance, if you are hosting OpenShift on top of AWS, you can leverage a fully managed database provided by Amazon RDS.
Making DAGs accessible to Airflow components
All three Airflow components Webserver, Scheduler, and Workers assume that the DAG definitions can be read from the local filesystem. The question is, how to make the DAGs available on the local filesystem in the container? There are two approaches to achieve this. In the first approach, a shared volume is created to hold all the DAGs. This volume is then attached to the Airflow pods. The second approach assumes that your DAGs are hosted in a git repository. A sidecar container is deployed along with the Airflow Server and Scheduler. This sidecar container synchronizes the latest version of your DAGs with the local filesystem periodically. For the Worker pods, the pulling of the DAGs from the git repository is done only once by the init container before the Worker is brought up.
Note that since Airflow 1.10.10, you can use the DAG Serialization feature. With DAG Serialization, the Scheduler reads the DAGs from the local filesystem and saves them in the database. The Airflow Webserver then reads the DAGs from the database instead of the local filesystem. For the Webserver container, you can avoid the need to mount a shared volume or configure git-sync if you enable the DAG Serialization.
To synchronize the DAGs with the local filesystem, I personally prefer using git-sync over the shared volumes approach. First, you want to keep you DAGs in the source control anyway to facilitate the development of the DAGs. Second, git-sync seems to be easier to troubleshoot and recover in the case of failure.
Airflow monitoring
As the old saying goes, “If you are not monitoring it, it’s not in production”. So, how can we monitor Apache Airflow running on OpenShift? Prometheus is a monitoring system widely used for monitoring Kubernetes workloads and I recommend that you consider it for monitoring Airflow as well. Airflow itself reports metrics using the statsd protocol, so you will need to deploy the statsd_exporter piece between Airflow and the Prometheus server. This exporter will aggregate the statsd metrics, convert them into Prometheus format and expose them for the Prometheus server to scrape.
Collecting Airflow logs
By default, Apache Airflow writes the logs to the local filesystem. If you have an RWX (ReadWriteMany) persistent volume available, you can attach it to the Webserver, Scheduler, and Worker pods to capture the logs. As the Worker logs are written to the shared volume, they are instantly accessible by the Webserver. This allows for viewing the logs live in the Web UI.
An alternative approach to handling the Airflow logs is to enable remote logging. With remote logging, the Worker logs can be pushed to the remote location like S3. The logs are then grabbed from S3 by the Webserver to display them in the Web UI. Note that when using an object store as your remote location, the Worker logs are uploaded to the object store only after the task run is complete. That means that you won’t be able to view the logs live in the Web UI while the task is still running.
The remote logging feature in Airflow takes care of the Worker logs. How can you handle Webserver and Scheduler logs when not using a persistent volume? You can configure Airflow to dump the logs to stdout. The OpenShift logging will collect the logs and send them to the central location.
Conclusion
In this article, we reviewed the Apache Airflow architecture on OpenShift. We discussed the role of individual Airflow components and described how they interact with each other. We discussed the Airflow’s shared database, explained how to make DAGs accessible to the Airflow components, and talked about Ariflow monitoring and log collection.
Apache Airflow can be deployed in several different ways. What is your favorite architecture for deploying Airflow? I would like to hear about your approach. If you have any further questions or comments, please add them to the comment section below.