This article is the first in a series of three articles which share my experience with troubleshooting the performance of Vert.x applications. The first article provides an overview of the Vert.x event loop model, the second acticle covers techniques to prevent delays on the event loop, and the third article focuses on troubleshooting of event loop delays.
Programming with Vert.x requires a good understanding of its event loop model. From what I saw in practice, delayed or blocked event loop threads are the number one contributor to performance problems with Vert.x applications. But don’t worry. In this article, we are going to review the event loop model.
Event loop theads and worker threads
Depending on how you register your handler with Vert.x APIs, Vert.x will either execute your handler using an event loop thread or a worker thread. There are only these two options in Vert.x. The determination whether the handler is going to be executed on an event loop thread or a worker thread is made at the time you register the handler and doesn’t change throughout the lifetime of your application. Take a look at this example:
| |
The API call vertx.executeBlocking() registered two handlers. Vert.x will call the blockingCodeHandler() using a worker thread and the resultHandler() using an event loop thread. Because there are restrictions on what code can be executed on event loop threads, you want to structure your code so that it’s clear to a casual reader whether a specific piece of code executes on a worker thread or an event loop thread.
Event loop frameworks like Vert.x employ a small amount of event loop threads at their core to do all the computational work. Using a low amount of threads minimizes the need for context switching which leads to a better performance than what a thread-per-request model can achieve.
In an ideal situation, your Vert.x application would exclusively use event loop threads.
The increased utilization of computing resources resulting in increased performance is a great benefit that event loop frameworks bring to the table. However, there are situations where employing worker threads is inevitable. We are going to show you some examples of such situations in the second article of this series. Just keep in mind that an excessive use of worker threads results in frequent context switching which will impact the overall performance of your application. This context switching negates the benefit of employing event loop frameworks like Vert.x in the first place.
Taking the event loop for a spin
The whole purpose of the event loop is to react to events which are delivered to the event loop by the operating system. Event loop processes those events by executing handlers. To explain how the event loop operates, let’s imagine a typical HTTP server application serving multiple client connections at the same time. There’s data being sent back and forth between the server and the client on each of the connections. And here is how the event loop handles it. First, the event loop waits for any of the events like incoming data available on the connection, or connection is ready to send more data. If any of those events happens, the event loop executes handlers that were registered to handle that specific event. For example, if there is incoming data available, the event loop calls the respective handler that stores the incoming data into a buffer and passes that buffer through a chain of handlers to your handler to process it. Handlers registered with a given event loop are executed one by one because the event loop is a single thread after all. After the processing of the event is finished, event loop returns back to wait for the next event.
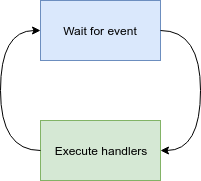
I would like to highlight that the event loop is a single thread that executes the handlers sequentially. In order for this scheme to work smoothly:
Handlers should not run code that would delay the event loop.
In the case that the application is under full load, the events are queuing up while the event loop is busy executing handlers. In this case, the event loop doesn’t really wait for events. Instead, it just picks up the next event and continues with executing handlers straight away.
On the other hand, if the application is idle and there are no events to process, the event loop will wait for events by blocking. It means the event loop thread will relinquish the CPU. Later on when the events arrive, the operating system scheduler will wake up the event loop thread again. Blocking while waiting for events is part of the event loop implementation and it is the only place where the event loop thread is supposed block. In contrast, handlers registered with the event loop should never issue a blocking call.
On my Linux machine, if I dump a stack trace of an idle event loop thread I will get this:
| |
Vert.x tool-kit is built on top of
Netty framework and the event loop implementation is actually part of Netty. In the stack trace you can see that the Java thread is executing the Netty’s event loop code which calls the Java NIO APIs which somewhere in the native code invokes the epoll_wait system call. This system call puts the event loop thread to sleep until the next event arrives.
Interestingly, while blocking in the epoll_wait system call, from the Java standpoint the thread is in a RUNNABLE state and not for example in the state BLOCKED which I would intuitively expect. JVM as an abstraction on top of the operating system has its own
definition of thread states. According to this definition the thread is indeed in the RUNNABLE state even when from the stand point of the operating system it is in the state interruptible sleep and hence blocked.
Conclusion
In this article, we familiarized ourselves with the event loop model which is rather different from the thread-per-request model. The next part in the series will cover techniques to prevent delays on the event loop.
Comment below if you found this article helpful or if you have suggestions for future blog subjects.