This blog will cover how to create a CI/CD pipeline that spans multiple OpenShift clusters. It will show an example of a Jenkins-based pipeline, and design a pipeline that uses Tekton.
Traditionally, CI/CD pipelines were implemented on top of bare metal servers and virtual machines. Container platforms like Kubernetes and OpenShift appeared on the scene only later on. As more and more workloads are migrating to OpenShift, CI/CD pipelines are headed in the same direction. Pipeline jobs are executed in containers in the cluster.
In the real world, companies don’t deploy a single OpenShift cluster but run multiple clusters. Why is that? They want to run their workloads in different public clouds as well as on-premise. Or, if they leverage a single platform provider, they want to run in multiple regions. Sometimes there is a need for multiple clusters in a single region, too. For example, when each cluster is deployed into a different security zone.
As there are plenty of reasons to use multiple OpenShift clusters, there is a need to create CI/CD pipelines that work across those clusters. The next sections are going to design such pipelines.
CI/CD pipeline using Jenkins
Jenkins is a legend among CI/CD tools. I remember meeting Jenkins back in the day when it was called Hudson but that’s old history. How can we build a Jenkins pipeline that spans multiple OpenShift clusters? An important design goal for the pipeline is to achieve a single dashboard that can display output of all jobs involved in the pipeline. I gave it some thought and realized that achieving a single dashboard pretty much implies using a single Jenkins master. This Jenkins master is connected with each of the OpenShift clusters. During the pipeline execution, Jenkins master can run individual tasks on any of the clusters. The job output logs are collected and sent to the master as usual. If we consider having three OpenShift clusters Dev, Test, and Prod, the following diagram depicts the approach:
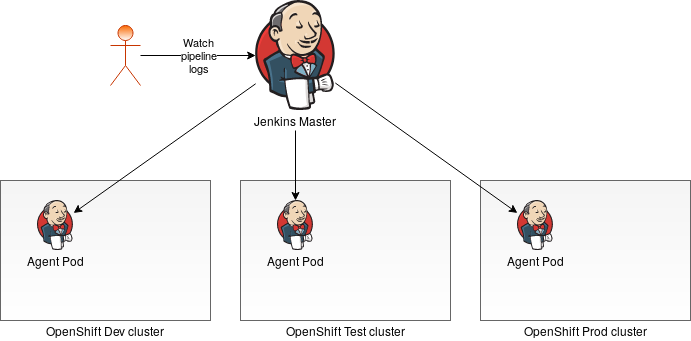
The Jenkins Kubernetes plugin is a perfect plugin for connecting Jenkins to OpenShift. It allows the Jenkins master to create ephemeral workers on the cluster. Each cluster can be assigned a different node label. You can run each stage of your pipeline on a different cluster by specifying the label. A simple pipeline definition for our example would look like this:
| |
OpenShift comes with a Jenkins template which can be found in the openshift project. This template allows you to create a Jenkins master that is pre-configured to spin up worker pods on the same cluster. Further effort will be needed to connect this master to additional OpenShift clusters. A tricky part of this set up is networking. Jenkins worker pod, after it starts up, connects back to the Jenkins master. This requires the master to be reachable from the worker running on any of the OpenShift clusters.
One last point I wanted to discuss is security. As long as the Jenkins master can spin up worker pods on OpenShift, it can execute arbitrary code on those workers. The OpenShift cluster has no means to control what code the Jenkins worker will run. The job definition is managed by Jenkins and it is solely up to the access controls in Jenkins to enforce which job is allowed to execute on which cluster.
Kubernetes-native Tekton pipeline
In this section, we are going to use Tekton to implement the CI/CD pipeline. In contrast to Jenkins, Tekton is a Kubernetes-native solution. It is implemented using Kubernetes building blocks and it is tightly integrated with Kubernetes. A single Kubernetes cluster is a natural boundary for Tekton. So, how can we build a Tekton pipeline that spans multiple OpenShift clusters?
I came up with an idea of composing the Tekton pipelines. To compose multiple pipelines into a single pipeline, I implemented the execute-remote-pipeline task that can execute a Tekton pipeline located on a remote OpenShift cluster. The task will tail the output of the remote pipeline while the remote pipeline is executing. With the help of this task, I can now combine Tekton pipelines across OpenShift clusters and run them as a single pipeline. For example, the diagram below shows a composition of three pipelines. Each of the pipelines is located on a different OpenShift cluster Dev, Test, and Prod:

The execution of this pipeline is started on the Dev cluster. The Dev pipeline will trigger the Test pipeline which will in turn trigger the Prod pipeline. The combined logs can be followed on the terminal:
| |
Note that this example is showing a cascading execution of Tekton pipelines. Another way of composing pipelines would be executing multiple remote pipelines in sequence.
Before moving on to the final section of this blog, let’s briefly discuss the pipeline composition in terms of security. As a Kubernetes-native solution, Tekton’s access control is managed by RBAC. Before the task running on a local cluster can trigger a pipeline on a remote cluster, it has to be granted appropriate permissions. These permissions are defined by the remote cluster. This way a remote cluster running in a higher environment (Prod) can impose access restrictions on the tasks running in the lower environment (Test). For example, a Prod cluster will allow the Test cluster to only trigger pre-defined production pipelines. The Test cluster won’t have permissions to create new pipelines in the Prod cluster.
Conclusion
This blog showed how to create CI/CD pipelines that span multiple OpenShift clusters using Jenkins and Tekton. It designed the pipelines and discussed some of the security aspects. The execute-remote-pipeline Tekton task was used to compose pipelines located on different OpenShift clusters into a single pipeline.
Needless to say, containerized pipelines work the same way on any OpenShift cluster regardless of whether the cluster itself is running on top of a public cloud or on-premise. The vision of the hybrid cloud is well showcased here.
Do you create pipelines that span multiple clusters? Would you like to share some of your design ideas? I would be happy to hear about your thoughts. Please, feel free to leave your comments in the comment section below.